
Introduction
Colaproxy vs Bright Data is a 2026 comparison of two major proxy providers used for web scraping, SEO tracking, and automation workflows. This article compares their performance, pricing, usability, and use cases to help you choose the best solution.
In today’s data-driven environment, web scraping has become an essential tool for businesses involved in price monitoring, SEO tracking, market research, and automation workflows. However, as websites continue to improve their anti-bot systems, maintaining stable and undetectable access to target platforms has become increasingly difficult.
Modern websites are no longer passively accepting traffic. They actively analyze IP reputation, request behavior, session patterns, and geographic consistency to determine whether traffic is human or automated. As a result, even well-designed scraping systems can fail without reliable proxy infrastructure.
When comparing Colaproxy vs Bright Data, it is important to understand how proxy services solve anti-bot challenges. In this Colaproxy vs Bright Data comparison, proxy services play a critical role in solving this challenge by distributing requests across multiple IP addresses and simulating real user behavior. Among the most widely used solutions in the industry are Colaproxy and Bright Data.

Overview of Colaproxy and Bright Data
What is Colaproxy?
Colaproxy is a modern proxy provider designed for users who need a simple, fast, and cost-effective solution for web scraping and automation tasks. Instead of focusing on complex enterprise configurations, it prioritizes ease of use, stable performance, and efficient deployment.
It is commonly used by developers, SEO professionals, and small to medium-sized businesses that require reliable residential IPs without managing complex infrastructure or advanced setup processes.
In practical terms, Colaproxy is built for teams that want to start scraping quickly and scale gradually without operational overhead.
What is Bright Data?
Bright Data is one of the largest enterprise-grade proxy networks in the world. It provides a comprehensive data collection infrastructure that includes residential proxies, mobile proxies, datacenter proxies, and advanced web scraping APIs.
It is primarily designed for enterprise organizations that require large-scale data extraction, advanced geo-targeting capabilities, and highly customizable scraping infrastructure.
Because of its scale and flexibility, Bright Data is often used by data engineering teams, analytics platforms, and large enterprises operating complex global data pipelines.
Feature Comparison
Although both providers offer residential proxy services, their design philosophy is fundamentally different. The comparison below highlights their key differences in practical usage scenarios.
| Feature | Colaproxy | Bright Data |
|---|---|---|
| Target Users | Developers, SEO teams, SMBs | Enterprises, large data teams |
| Setup Complexity | Simple and fast integration | Complex configuration requiring expertise |
| Pricing Model | Affordable and flexible | Premium enterprise pricing |
| Ease of Use | Beginner-friendly | Requires technical knowledge |
| Proxy Types | Residential & Mobile IPs | Residential, Mobile, Datacenter |
| Geo-targeting | Standard global coverage | Advanced and highly granular targeting |
| Best For | SEO, scraping, automation workflows | Large-scale enterprise data pipelines |
From a practical perspective, the most important difference is not feature count, but operational complexity. Colaproxy emphasizes speed and simplicity, while Bright Data focuses on deep infrastructure control and scalability.
Performance and Reliability
Colaproxy Performance
Colaproxy is optimized for lightweight to medium-scale scraping operations. It provides stable residential IPs that are suitable for common use cases such as search engine scraping, e-commerce monitoring, and social media automation.
One of its main strengths is consistency combined with simplicity. Users can typically start scraping within minutes without dealing with complex configuration or infrastructure setup. This makes it particularly effective for fast-moving teams and iterative workflows.
Bright Data Performance
Bright Data offers one of the most extensive proxy infrastructures in the industry, capable of supporting extremely large-scale scraping operations with advanced customization and control.
It excels in environments where millions of requests need to be processed daily, and where fine-grained geo-targeting and session control are required.
However, this level of capability comes with increased complexity. It is generally better suited for organizations with dedicated engineering teams responsible for managing and optimizing scraping infrastructure.
Pricing Comparison
Pricing is one of the most important factors when choosing between these two providers, and the difference is significant.
Colaproxy focuses on affordability and accessibility. It offers straightforward pricing models designed for individuals, startups, and small teams, without requiring long-term contracts or complex billing structures.
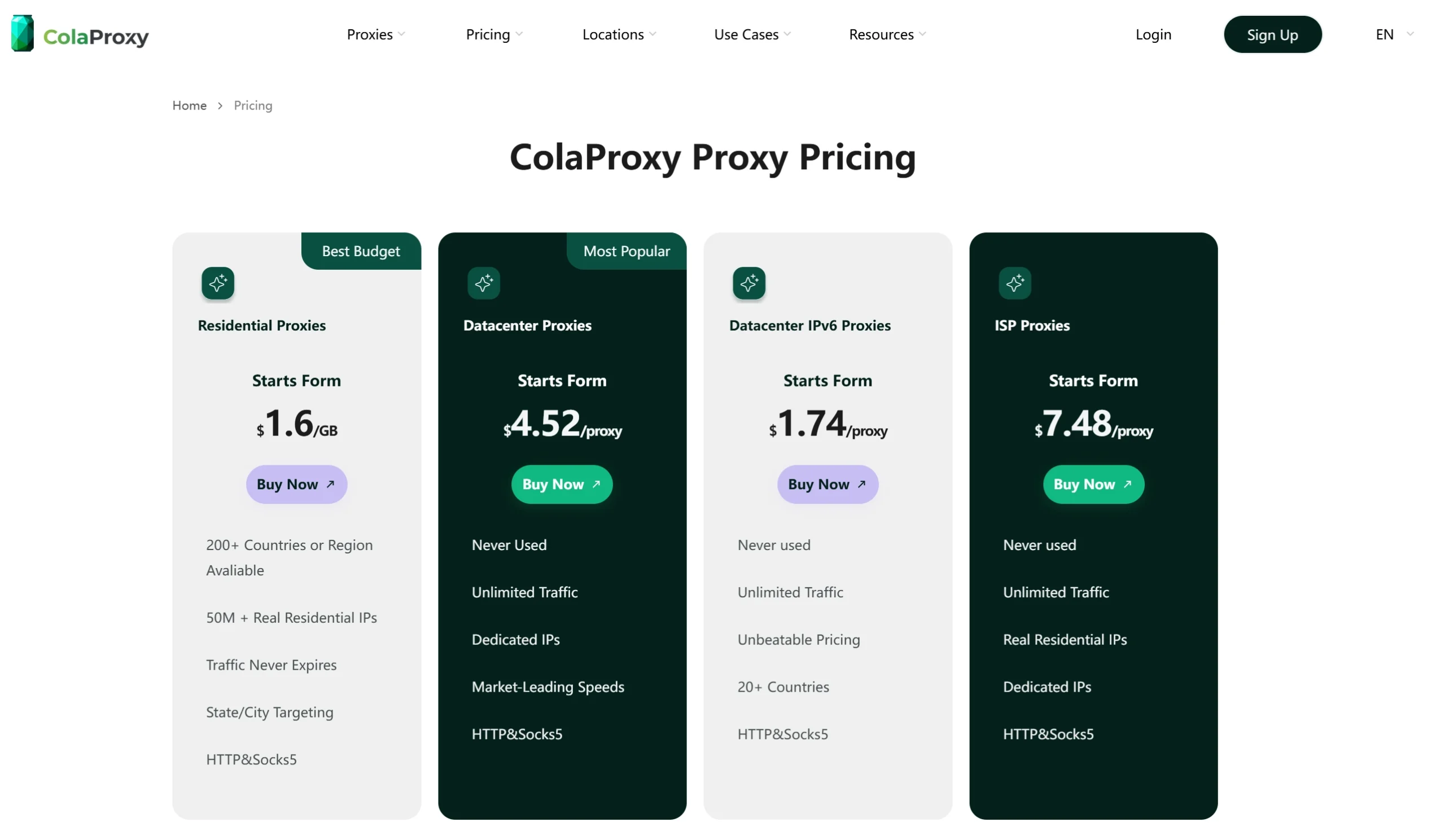{kind=link}
Bright Data, on the other hand, follows a premium enterprise pricing model. While it offers more advanced capabilities and infrastructure depth, the overall cost is significantly higher, especially for smaller teams or lightweight use cases.
In most cases, the decision comes down to whether the priority is cost efficiency or enterprise-level scalability.
Use Case Suitability
Different proxy services perform better depending on the specific use case. The table below summarizes which provider is better suited for common scenarios.
| Use Case | Recommended Provider |
|---|---|
| Amazon product scraping | Colaproxy |
| SEO rank tracking | Colaproxy |
| Social media automation | Colaproxy |
| Enterprise data pipelines | Bright Data |
| Large-scale analytics | Bright Data |
| Advanced geo-targeted scraping | Bright Data |
Ease of Integration
One of Colaproxy’s key advantages is its ease of integration. It can be quickly configured and used with common scraping frameworks and automation tools, allowing teams to focus on data extraction rather than infrastructure management.
Bright Data provides a more advanced API-driven integration system, which offers greater control but requires more development effort and technical understanding. This makes onboarding slower but more flexible for enterprise environments.
Final Verdict
Both Colaproxy and Bright Data are powerful proxy solutions, but they are designed for fundamentally different types of users and workflows.
Colaproxy is best suited for users who prioritize simplicity, affordability, and fast deployment. It is ideal for SEO tracking, automation workflows, and web scraping tasks where operational efficiency matters more than infrastructure complexity.
Bright Data is better suited for enterprise-level organizations that require large-scale data collection capabilities, advanced customization, and deep infrastructure control.
For most developers, startups, and small to mid-sized teams, Colaproxy provides a more practical and cost-effective solution for real-world scraping needs in 2026.
Conclusion
Choosing the right proxy provider ultimately depends on your technical requirements, budget, and scale of operations. While Bright Data remains a powerful enterprise-grade solution, Colaproxy offers a more accessible and efficient approach for everyday scraping and automation workflows.
In a modern scraping environment where speed, cost, and simplicity often matter as much as raw power, Colaproxy stands out as a strong practical choice for most users.