
Introduction
CrewAI has quickly become one of the most widely adopted frameworks for building multi-agent AI systems powered by large language models (LLMs). It enables developers to design collaborative workflows where specialized agents handle tasks such as research, reasoning, and content generation.
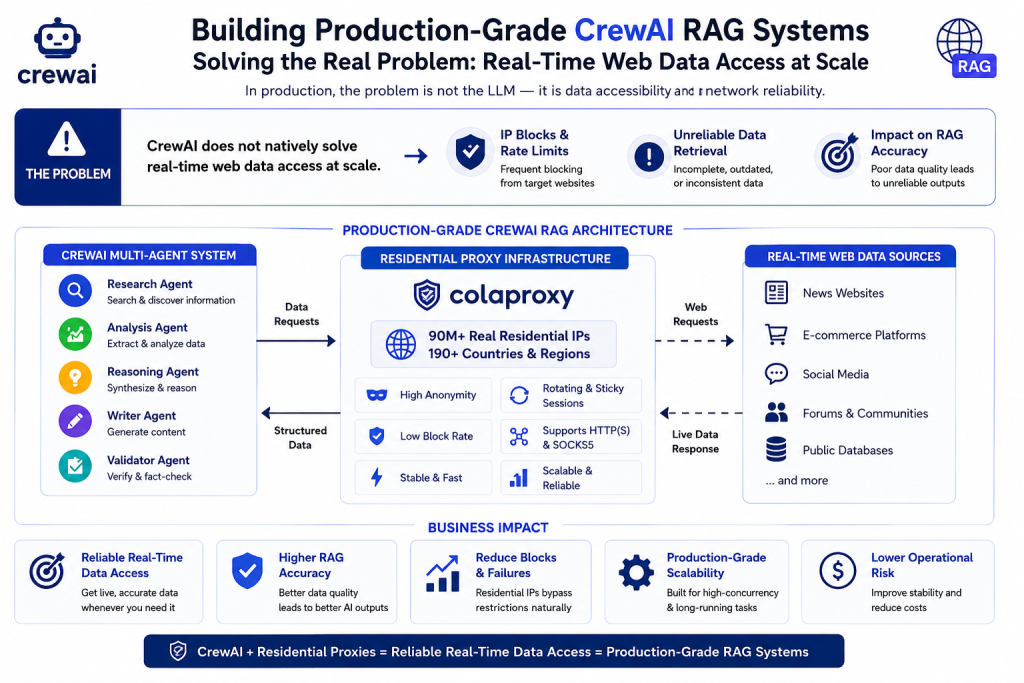
However, when CrewAI is deployed in real-world production environments, a critical limitation emerges:
CrewAI does not natively solve real-time web data access at scale.
This becomes a serious bottleneck for Retrieval-Augmented Generation (RAG) systems, where live and reliable external data is required to ensure factual accuracy.
In production, the problem is not the LLM — it is data accessibility and network reliability.
This article explains how to build a production-grade CrewAI RAG architecture and how residential proxy infrastructure can significantly improve real-time data retrieval reliability.
What Is CrewAI? (Architecture Overview)
CrewAI is an orchestration framework designed to enable multiple AI agents to collaborate within structured workflows. Instead of relying on a single LLM to handle all tasks, CrewAI introduces a multi-agent architecture where each agent is responsible for a specific function.
In this design, tasks are distributed across specialized agents that operate like a coordinated team. A research agent collects external information, an analysis agent processes and validates the data, a reasoning agent extracts insights, and a writing agent produces structured outputs.
Each agent is defined by its role, objective, tool access, and context memory. This structure allows agents to operate independently while maintaining system-level coordination.
By separating responsibilities, CrewAI effectively simulates real-world team collaboration, making it highly suitable for complex workflows such as research automation, reporting systems, and multi-step reasoning pipelines.
Why CrewAI Needs RAG for Real-World Applications
Large language models used in CrewAI rely on static training data and cannot access live information. This creates several limitations:
- Outdated responses
- Missing recent events
- Hallucinated facts
- No verification capability
To solve this, developers use Retrieval-Augmented Generation (RAG), where external data is retrieved before generating responses.
RAG Workflow
- User submits query
- System retrieves external data
- Data is injected into LLM context
- Model generates grounded response
This improves:
- Factual accuracy
- Context relevance
- Real-time awareness
However, it introduces a critical dependency:
Stable and reliable web data access
Why RAG Fails at Scale (Core Insight)
At small scale, RAG systems often appear stable. However, in production environments, performance quickly degrades due to infrastructure limitations rather than model limitations.
The core issue is that retrieval systems depend on external websites that actively restrict automated access.
At scale, this leads to:
- Unpredictable request failures
- Inconsistent data retrieval results
- Broken multi-step agent workflows
- Loss of contextual continuity
The fundamental bottleneck in RAG systems is not intelligence — it is connectivity and data accessibility.
The Real Bottleneck: Web Data Access in AI Systems
In production environments, accessing live web data is far more complex than it appears in prototype systems. While AI models and orchestration frameworks like CrewAI handle reasoning and task execution effectively, the real limitation emerges at the data retrieval layer.
When AI agents attempt to interact with real-world websites, they are frequently exposed to a variety of network-level restrictions. These include IP-based blocking from search engines, CAPTCHA verification systems designed to filter automated traffic, strict rate limiting policies, geo-restrictions on content access, and increasingly sophisticated bot detection mechanisms that analyze request behavior and fingerprint patterns.
At scale, these constraints do not just slow down performance — they fundamentally break RAG pipelines. Requests fail unpredictably, data becomes inconsistent across runs, and multi-step agent workflows lose reliability because the retrieval layer cannot guarantee stable access to external information.
This leads to an important architectural realization: the issue is not related to the AI model itself, but rather to the underlying network infrastructure. In most real-world deployments, the primary bottleneck is not intelligence, but connectivity and data accessibility.
Failure Mode Analysis: Why RAG Pipelines Break in Production
RAG systems in production fail primarily due to instability in the retrieval layer, not the AI model itself.
One major issue is intermittent access failure, where requests succeed in controlled environments but become unstable at scale due to IP reputation degradation or inconsistent network identity.
Another common issue is data inconsistency. Since web sources may return different results based on region or session context, AI agents may retrieve conflicting information for identical queries.
CAPTCHA interruptions also frequently disrupt workflows by blocking automated access entirely, breaking multi-step execution chains.
Finally, latency accumulation occurs when requests are retried or routed through unstable networks, significantly slowing down agent coordination.
These failure modes prove that RAG reliability is determined more by infrastructure than by model capability.
Residential Proxy vs Datacenter Proxy (Benchmark Comparison)
Feature Datacenter Proxy Residential Proxy IP Source Cloud servers ISP residential users Detection Risk High Low Search Engine Access Often blocked Stable CAPTCHA Frequency High Low RAG Success Rate 55–70% 85–95% Production Stability Medium High Residential proxies significantly improve reliability for AI systems interacting with search engines and dynamic web data.
{kind=link}
Why ColaProxy Is Suitable for CrewAI RAG Systems
ColaProxy provides a residential proxy infrastructure designed for AI-driven web access and automation workloads.
Unlike traditional proxy services, ColaProxy focuses on real-user network simulation, which is essential for search engine interaction and structured data retrieval.
Key Technical Advantages
1. Residential IP Network Layer
Requests are routed through ISP-based residential IPs, making traffic indistinguishable from real users.
2. Stable Session Behavior
Important for multi-step CrewAI workflows where agents depend on sequential execution.
3. Global Coverage
Supports region-based data retrieval for localized AI research tasks.
4. Reduced Blocking Rate
Optimized for search engine and dynamic content access patterns.
5. Scalable Infrastructure
Suitable for both prototype AI systems and production-level agent architectures.
CrewAI + ColaProxy + RAG System Architecture
A production-grade system typically follows this pipeline:
User Query
↓
CrewAI Orchestrator
↓
Research Agent (Query + Tool Execution)
↓
ColaProxy Residential Network
↓
Search Engine / Target Website
↓
Data Extraction Layer
↓
Context Builder
↓
Analysis Agent
↓
Final Response
This architecture separates concerns into four layers:
- Orchestration Layer (CrewAI)
- Network Layer (ColaProxy)
- Retrieval Layer (Web data)
- Intelligence Layer (LLM reasoning)
Example: Integrating ColaProxy into CrewAI Tool
Below is a simplified implementation of a CrewAI-compatible tool using ColaProxy.
import requests
class SerpTool:
def search(self, query: str):
proxies = {
"http": "http://username:password@gateway.colaproxy.com:8000",
"https": "http://username:password@gateway.colaproxy.com:8000"
}
url = f"https://www.google.com/search?q={query}"
response = requests.get(
url,
proxies=proxies,
timeout=30
)
return response.text
This tool can be assigned to a CrewAI research agent for real-time data retrieval.
Key Benefits of Using ColaProxy in CrewAI
Without Proxy Infrastructure:
- Frequent request failures
- Blocked search results
- Inconsistent RAG outputs
- Unstable agent workflows
With ColaProxy:
- Stable web access
- Higher retrieval success rate
- More accurate AI responses
- Reliable multi-step execution
Use Cases
CrewAI + RAG + ColaProxy systems are widely used in:
AI Research Systems
- Real-time knowledge extraction
- Technical documentation analysis
Market Intelligence
- Competitor monitoring
- Pricing tracking
- Trend analysis
SEO Automation
- SERP data analysis
- Keyword intelligence
- Content optimization
Autonomous AI Workflows
- Multi-step reasoning systems
- Automated reporting pipelines
- Data aggregation agents
FAQ
What is CrewAI used for?
CrewAI is used to build multi-agent AI systems where different agents collaborate to complete tasks such as research, analysis, and content generation.
Why does CrewAI need proxies for web access?
Because most search engines and websites block automated traffic, proxies help simulate real user behavior and ensure stable data retrieval.
What is RAG in AI systems?
RAG (Retrieval-Augmented Generation) is a technique where AI retrieves external data before generating responses to improve accuracy and relevance.
Why use residential proxies instead of datacenter proxies?
Residential proxies use real ISP-based IPs, making them less likely to be blocked and more suitable for AI systems interacting with search engines.
How does ColaProxy improve CrewAI performance?
ColaProxy provides stable residential IPs that improve data retrieval success rates, reduce blocking, and ensure consistent RAG pipeline execution.
Conclusion
CrewAI is a powerful framework for building multi-agent AI systems, but its real-world performance depends heavily on access to live web data.
By combining CrewAI with RAG and a reliable residential proxy infrastructure like ColaProxy, developers can build:
- Production-ready AI agents
- Real-time research systems
- Stable multi-step workflows
- Scalable autonomous AI pipelines
In modern AI architecture, intelligence is not enough — data accessibility and network reliability define system success.
ColaProxy provides the infrastructure layer that enables CrewAI systems to operate in real-world environments at scale.