In 2026, Playwright web scraping has become the go-to solution for extracting data from modern, JavaScript-heavy websites. From Amazon and Shopee to Google and TikTok, today’s platforms rely heavily on dynamic rendering, making traditional scraping methods increasingly ineffective.
Unlike HTTP-based tools, Playwright operates at the browser level, allowing developers to fully render pages, execute JavaScript, and simulate real user interactions.
However, there’s a catch.
Modern websites are no longer passive. They actively detect and block automated traffic using advanced anti-bot systems. This means:
Playwright alone is no longer enough for scalable web scraping.
To succeed in 2026, you need a combination of:
- Browser automation (Playwright)
- Proxy infrastructure (residential IPs)
- Behavioral simulation (anti-detection logic)
This guide breaks down how to build a production-grade scraping system that actually works.
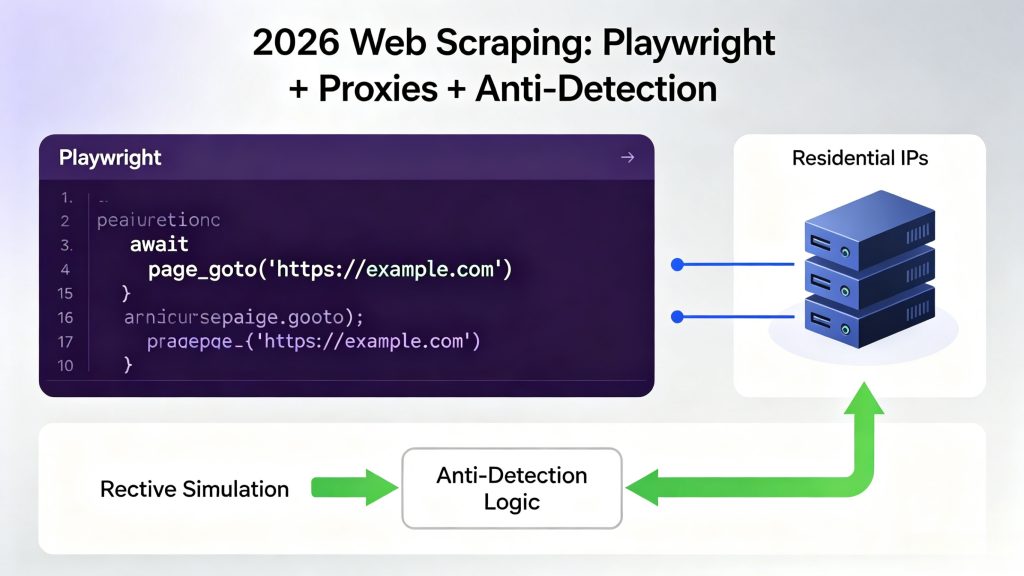
Table of Contents
Why Playwright Web Scraping Became an Industry Standard
Playwright is widely adopted because it operates at the browser rendering layer rather than the HTTP request layer. This allows it to interact with modern web applications as a real user would.
With Playwright, developers can:
- Render JavaScript-heavy websites
- Execute modern front-end frameworks (React, Vue, Angular)
- Maintain authentication sessions
- Simulate user interactions such as clicks and scrolling
- Handle dynamic content loading and infinite scroll pages
These capabilities make it significantly more reliable than traditional HTTP-based scraping tools in modern web environments.
However, this strength also introduces a limitation: Playwright still operates from a single digital identity unless external infrastructure is introduced.

Why Modern Websites Block Playwright Scraping
Modern anti-bot systems in 2026 no longer rely on simple rule-based detection. Instead, they analyze multiple layers of behavioral and network signals to determine whether a visitor is human or automated.
Key detection layers include:
Network-level signals
- IP reputation scoring
- ASN classification (datacenter vs residential)
- Request frequency patterns
Browser fingerprinting
- Canvas and WebGL rendering signatures
- Font and system configuration
- TLS/JA3 handshake patterns
Behavioral signals
- Mouse movement randomness
- Scroll velocity and timing
- Click patterns and navigation flow
Session correlation
- Repeated browsing patterns
- Cross-session fingerprint matching
- Behavioral similarity clustering
When inconsistencies are detected across these layers, websites may trigger CAPTCHA challenges, throttle requests, or permanently block access.
This makes scraping without infrastructure support unstable at scale.
The Role of Residential Proxies in Web Scraping
Residential proxies solve the core limitation of Playwright by introducing identity distribution at the network level.
Unlike datacenter proxies, residential proxies use real ISP-assigned IP addresses. This makes traffic appear as if it originates from genuine users rather than automated systems.
Key advantages include:
- Higher trust scores across major platforms
- Lower CAPTCHA trigger rates
- Access to geo-restricted content
- Improved session stability
- Reduced detection probability
In modern scraping architectures, residential proxies are not optional—they are essential infrastructure.
Best Proxy Type for Playwright Web Scraping
There are three main proxy types used in scraping:
1. Datacenter Proxies
- Fast and cheap
- Easy to detect
- High block rate on major platforms
2. ISP Proxies
- More stable than datacenter
- Moderate trust level
- Limited geographic coverage
3. Residential Proxies (Recommended)
{kind=link}
- Real user IPs
- Highest trust level
- Best for anti-bot bypass
- Ideal for large-scale scraping
👉 For Playwright web scraping, residential proxies consistently deliver the highest success rates.
How ColaProxy Supports Playwright Web Scraping
ColaProxy provides a globally distributed residential and mobile proxy network designed for high-scale automation and data extraction systems.
When integrated with Playwright, it enables:
- Global IP rotation across real ISP networks
- Multi-region scraping capabilities
- Stable long-session browsing environments
- Reduced anti-bot detection frequency
- High concurrency scraping performance
Common enterprise use cases include:
- E-commerce pricing intelligence (Amazon, Shopee)
- Search engine result tracking (Google SERP monitoring)
- Social media data extraction (TikTok analytics)
- Competitive market intelligence systems
- Large-scale structured data collection pipelines
Scalable Playwright Scraping Architecture
A production-ready scraping system must be designed as a distributed pipeline rather than a single automation script.
Playwright Browser Automation Layer
↓
ColaProxy Residential / Mobile Proxy Layer
↓
Behavior Simulation & Anti-Detection Layer
↓
Target Websites (Amazon / Shopee / Google / TikTok)
↓
Data Processing & Storage SystemWhy this architecture works
This layered structure separates execution, identity, and data processing. As a result, it provides:
- Reduced fingerprint correlation risk
- Horizontal scalability across regions
- Improved resistance to blocking systems
- Higher overall scraping success rates
Playwright Proxy Integration Example
Below is a basic implementation of proxy integration in Playwright:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({
proxy: {
server: 'http://proxy-ip:port',
username: 'username',
password: 'password'
}
});
const page = await browser.newPage();
await page.goto('https://example.com');
console.log(await page.title());
await browser.close();
})();While simple in structure, the effectiveness of this setup depends entirely on the quality of the proxy infrastructure behind it.
Common Failure Patterns in Web Scraping
At scale, most scraping failures are caused by predictable patterns:
IP reuse patterns
Repeated use of the same IP reduces trust scores and triggers blocking mechanisms.
Behavioral consistency patterns
Identical navigation and interaction flows lead to bot classification.
Geo-mismatch patterns
Discrepancies between IP location and expected user behavior raise suspicion.
Fingerprint correlation patterns
Repeated browser signatures across sessions allow identity clustering.
These issues cannot be resolved through Playwright configuration alone and require infrastructure-level diversification.
Best Practices for Stable Scraping Systems
To maintain long-term scraping stability in 2026, systems should follow these principles:
- Rotate residential IPs at the session level
- Introduce randomized delays between actions
- Simulate natural browsing behavior
- Distribute traffic across multiple geographic regions
- Avoid repetitive navigation patterns
- Monitor HTTP response anomalies such as 403 and 429 errors
When combined with a reliable proxy infrastructure, these practices significantly improve scraping success rates.
Conclusion
In 2026, Playwright web scraping is no longer just a browser automation technique. It has become a full-scale infrastructure challenge involving identity management, behavioral simulation, and distributed proxy networks.
The most effective architecture today is:
👉 Playwright + Residential Proxy Network + Behavioral Simulation Layer
By integrating a high-quality infrastructure such as ColaProxy, organizations can achieve:
- Stable large-scale data extraction
- Lower detection and blocking rates
- Multi-region access to global platforms
- Scalable enterprise-grade scraping systems
Ultimately, success in modern web scraping is no longer determined by the tool itself, but by the infrastructure behind it.