
In 2026, web scraping has evolved into a highly competitive technical field where simple automation scripts are no longer enough. Modern websites such as Google, Amazon, TikTok, Instagram, LinkedIn, and Shopee now use advanced anti-bot systems powered by machine learning, browser fingerprint analysis, and IP reputation scoring.
As a result, traditional scraping methods fail quickly, even when using powerful tools like Puppeteer.
This guide explains why scraping fails today, how Puppeteer Stealth works, and why combining it with residential proxy infrastructure such as ColaProxy is essential for building stable, scalable, and production-grade scraping systems.
{kind=link}
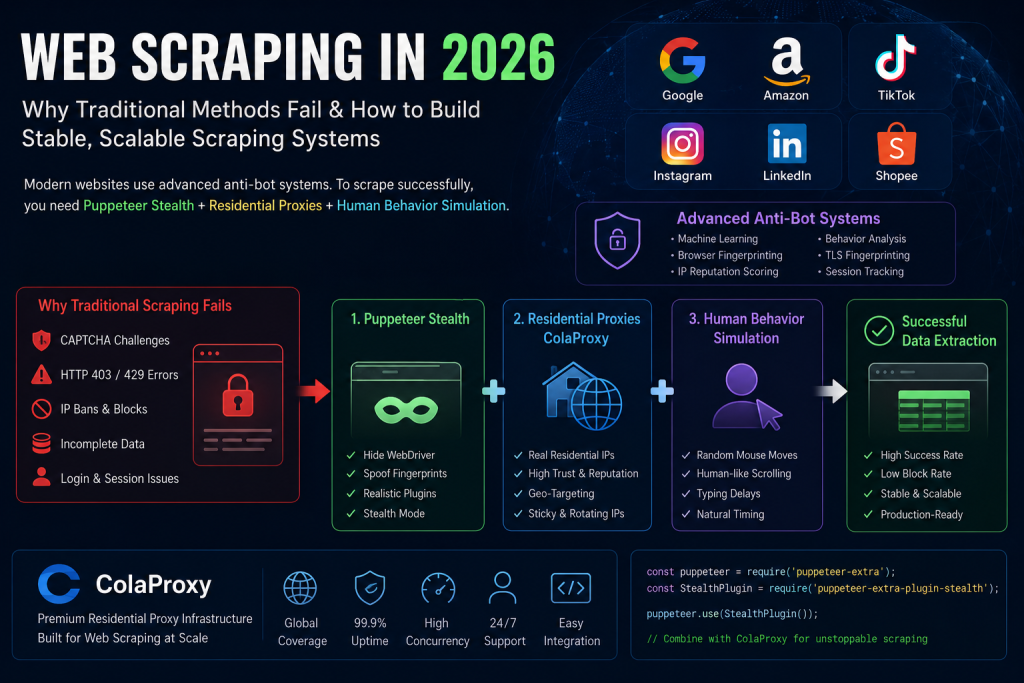
Why Traditional Puppeteer Scraping Fails in 2026
Several years ago, running Puppeteer in headless mode was often enough for scraping many websites. Today, that approach fails almost immediately on most major platforms.
The reason is simple: websites have become significantly more intelligent in detecting automated traffic.
Modern anti-bot systems do not rely on a single signal. Instead, they analyze dozens of layers simultaneously. This includes browser fingerprints, JavaScript execution behavior, mouse movement patterns, TLS handshake signatures, session consistency, IP reputation, ASN classification, and even interaction timing entropy.
When a Puppeteer instance launches with default settings, many detectable characteristics become visible immediately. The browser may expose automation-related variables such as navigator.webdriver, missing plugins, inconsistent rendering behavior, unusual graphics fingerprints, or unrealistic timing patterns. Even if one signal is hidden, the remaining signals can still expose the automation environment.
This explains why developers often encounter problems such as:
| Common Scraping Issue | Typical Cause |
|---|---|
| CAPTCHA challenges | Suspicious browser fingerprint |
| HTTP 403 Forbidden | Low IP reputation |
| HTTP 429 Too Many Requests | Aggressive request patterns |
| Login verification loops | Session inconsistency |
| Sudden account bans | Automation behavior detection |
| Incomplete page rendering | JavaScript execution blocking |
The challenge becomes even greater when scraping platforms like Google SERP, Amazon product pages, TikTok feeds, or Shopee listings because these websites invest heavily in anti-scraping infrastructure.
As a result, modern web scraping requires much more than browser automation alone.
What Puppeteer Stealth Actually Does
Puppeteer Stealth is essentially an anti-detection layer built on top of Puppeteer.
Instead of changing how scraping works, it modifies how the browser appears to target websites.
The plugin patches many detectable browser properties that typically reveal automation behavior. For example, it can hide the webdriver flag, simulate realistic browser plugins, spoof language settings, modify Chrome-specific fingerprints, and improve headless browser consistency.
A basic implementation usually looks like this:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({
headless: true
});
const page = await browser.newPage();
await page.goto('https://example.com');
console.log(await page.title());
await browser.close();
})();
While this improves browser stealth significantly, it still does not solve the biggest issue in web scraping:
Your IP identity.
Even the most realistic browser fingerprint can still be blocked if requests originate from suspicious networks or repeated datacenter IP ranges.
This is why modern scraping systems rely heavily on residential proxy infrastructure.
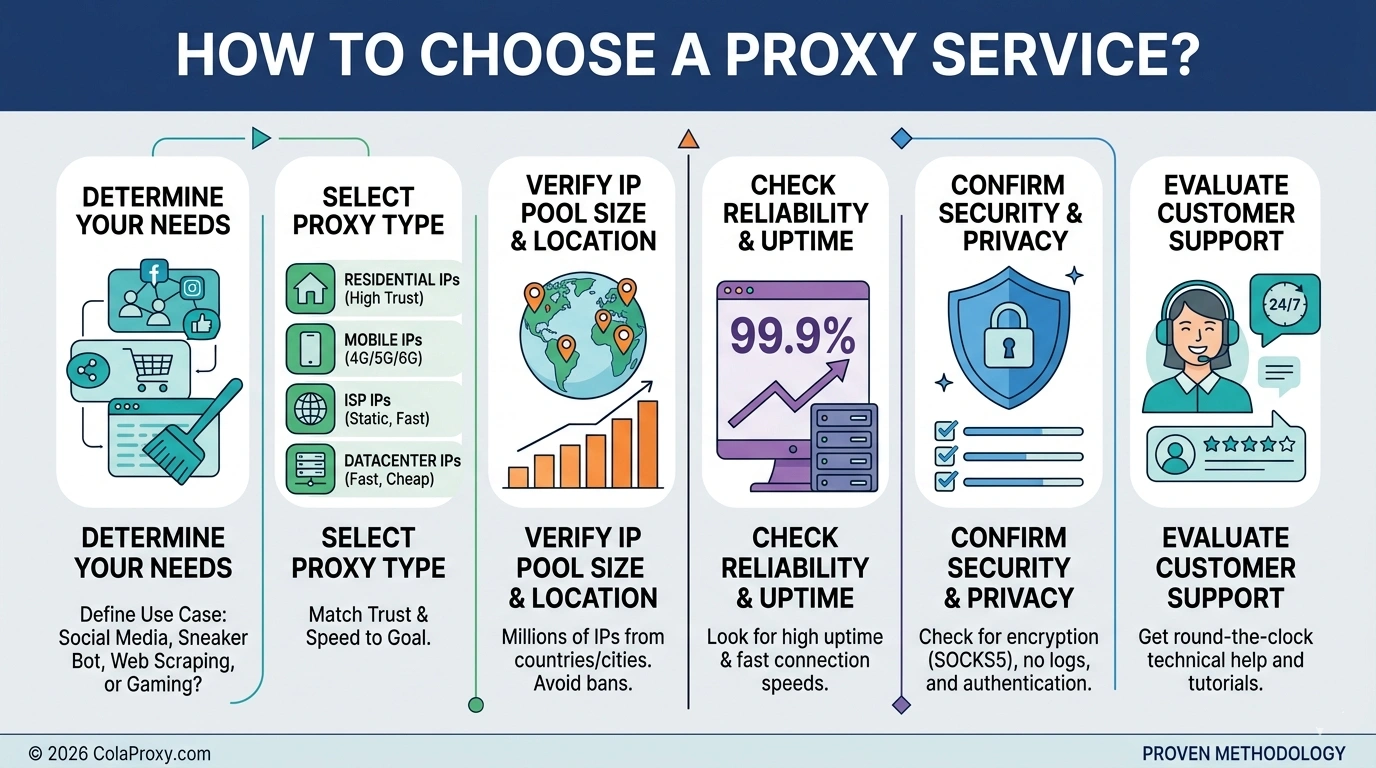
Why Residential Proxies Matter More Than Ever
{kind=link}
In 2026, IP reputation has become one of the strongest signals in anti-bot systems.
Most websites can immediately identify whether traffic originates from:
- Datacenter networks
- Cloud providers
- VPN services
- Residential ISP networks
- Mobile carriers
Datacenter proxies are fast and inexpensive, but they are also highly detectable. Large platforms already maintain extensive blacklists of cloud-hosted IP ranges.
Residential proxies work differently.
Instead of routing traffic through servers, residential proxies use real IP addresses assigned by internet service providers. From the target website’s perspective, requests appear to originate from ordinary users browsing from home networks.
This dramatically reduces suspicion scores.
The difference becomes especially noticeable in environments involving:
- Amazon scraping
- Google SERP extraction
- TikTok automation
- Sneaker monitoring
- Social media scraping
- E-commerce intelligence gathering
The following comparison highlights the difference between proxy types in modern scraping environments:
| Proxy Type | Detection Risk | Speed | Trust Level | Best Use Case |
|---|---|---|---|---|
| Datacenter Proxy | High | Very Fast | Low | Simple scraping |
| ISP Proxy | Medium | Fast | Medium | Medium-security targets |
| Residential Proxy | Very Low | Moderate | High | Enterprise scraping |
| Mobile Proxy | Lowest | Moderate | Very High | Social platforms |
Because of this, developers increasingly combine Puppeteer Stealth with residential proxies to create a more realistic browsing identity.
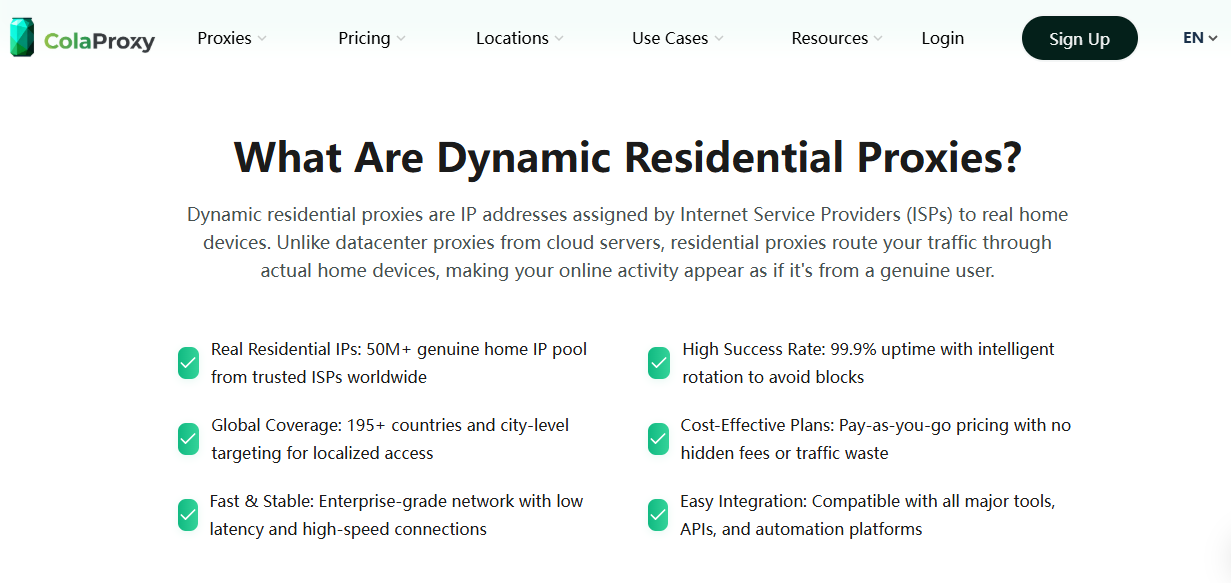
How ColaProxy Improves Puppeteer Stealth Scraping
ColaProxy provides residential proxy infrastructure optimized for browser automation and large-scale scraping operations.
When combined with Puppeteer Stealth, ColaProxy helps reduce detection across multiple layers simultaneously.
Key advantages include:
| ColaProxy Feature | Scraping Benefit |
|---|---|
| Residential IP pool | Higher trust scores |
| Global geo-targeting | Region-specific scraping |
| Sticky sessions | Stable login persistence |
| Rotating proxies | Reduced request correlation |
| ISP-grade reputation | Lower CAPTCHA rates |
| High concurrency support | Scalable scraping |
| SOCKS5 and HTTP support | Flexible integration |
| Long-session stability | Better browser continuity |
This combination becomes extremely effective against sophisticated anti-bot systems.
For example:
- Google monitors geographic consistency and SERP interaction patterns
- Amazon tracks session continuity and browsing entropy
- TikTok analyzes behavioral realism and IP trust
- LinkedIn evaluates automation timing and session fingerprints
- Shopee measures browsing velocity and regional authenticity
Without residential proxy infrastructure, browser stealth eventually becomes insufficient.
Building a Stable Puppeteer Stealth Scraping Workflow
A modern scraping workflow should never rely on a single script running from a static environment.
Instead, successful systems separate scraping responsibilities into multiple layers.
A typical production architecture looks like this:
Puppeteer Stealth Browser Layer
↓
Residential Proxy Network (ColaProxy)
↓
Behavior Simulation Layer
↓
Target Website
↓
Data Parsing & Storage
This structure helps isolate risk factors.
The browser layer focuses on rendering and automation. The proxy layer manages network identity. The behavior layer introduces human-like browsing patterns.
Together, these layers significantly reduce detection probability.
Advanced Puppeteer Stealth Configuration
Simply enabling stealth mode is often not enough for large-scale scraping.
Modern systems usually require additional optimizations such as:
- Randomized viewport sizes
- Dynamic user agents
- Human-like scrolling behavior
- Request timing randomization
- Browser context isolation
- Session-based proxy rotation
The following example demonstrates a more advanced Puppeteer Stealth setup using residential proxies:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({
headless: true,
args: [
'--no-sandbox',
'--disable-setuid-sandbox'
]
});
const page = await browser.newPage();
await page.authenticate({
username: 'proxy-user',
password: 'proxy-pass'
});
await page.goto('https://www.google.com', {
waitUntil: 'networkidle2'
});
await page.setViewport({
width: 1366,
height: 768
});
await page.mouse.move(200, 300);
console.log(await page.title());
await browser.close();
})();
This setup creates a much more realistic browsing environment than a default Puppeteer configuration.
Human Behavior Simulation
Many scraping systems fail because they behave too efficiently.
Real users do not:
- Click instantly
- Scroll perfectly
- Load hundreds of pages per minute
- Maintain mathematically consistent timing
Modern anti-bot systems use entropy analysis to identify unrealistic browsing behavior.
Effective scraping systems introduce randomness into:
- Mouse movement
- Scroll behavior
- Typing delays
- Navigation timing
- Session duration
- Interaction order
Example:
await page.mouse.move(
100 + Math.random() * 200,
200 + Math.random() * 300
);
await page.waitForTimeout(
Math.random() * 1500 + 500
);
await page.keyboard.type(
'best residential proxies',
{
delay: 80 + Math.random() * 60
}
);Behavioral realism significantly reduces detection probability.
Benchmark: Stealth vs Non-Stealth Scraping
In practical testing environments, stealth and residential proxies dramatically improve scraping success rates.
Example benchmark across protected websites:
| Configuration | Success Rate | CAPTCHA Frequency |
|---|---|---|
| Puppeteer only | 31% | Very High |
| Puppeteer + Datacenter Proxy | 46% | High |
| Puppeteer + Stealth | 63% | Medium |
| Puppeteer + Stealth + Residential Proxy | 91% | Low |
| Puppeteer + Stealth + ColaProxy | 96% | Very Low |
These improvements become even more noticeable on heavily protected platforms like Google and Amazon.
Performance Optimization for Large-Scale Scraping
Enterprise scraping systems must also optimize performance and cost efficiency.
Blocking unnecessary resources reduces bandwidth and speeds up page loading.
Example:
await page.setRequestInterception(true);
page.on('request', (req) => {
const blockedResources = [
'image',
'media',
'font'
];
if (
blockedResources.includes(
req.resourceType()
)
) {
req.abort();
} else {
req.continue();
}
});Additional optimization strategies include:
- Browser pooling
- Context recycling
- Queue-based scraping
- Distributed workers
- Smart retry systems
- Adaptive concurrency control
Professional scraping infrastructure increasingly resembles distributed cloud architecture rather than simple automation scripts.
Common Mistakes That Still Trigger Detection
Even with Puppeteer Stealth enabled, many scraping systems still fail because of operational mistakes.
One common issue is excessive request frequency. Human users do not load hundreds of pages per minute from the same browsing session.
Another major problem is browser fingerprint reuse. Running multiple sessions with identical browser characteristics creates highly detectable clustering patterns.
Geographic inconsistencies also create suspicion. For example, accessing a US-only Amazon page while using an unrelated regional browsing pattern may increase detection risk.
Behavior repetition is another important factor. Identical mouse movements, scrolling timing, or navigation sequences are easier for anti-bot systems to identify.
In 2026, successful scraping depends heavily on variability.
The Future of Web Scraping and Browser Automation
The web scraping industry is rapidly shifting toward infrastructure-driven architectures.
The biggest change is that scraping success no longer depends primarily on automation frameworks themselves. Instead, it depends on the quality of the surrounding environment:
- Proxy reputation
- Browser identity consistency
- Behavioral realism
- Session management
- Distributed request infrastructure
This is why companies investing in large-scale data extraction increasingly focus on stealth browsing environments combined with residential proxy networks.
Puppeteer Stealth is no longer simply an optional plugin.
It has become part of a broader anti-detection strategy required for modern browser automation.
Final Thoughts
Puppeteer Stealth remains one of the most powerful tools for preventing detection in web scraping, but it should never be viewed as a standalone solution.
Modern anti-bot systems analyze far more than browser automation signals alone. IP reputation, session consistency, behavioral patterns, and browser fingerprints all contribute to detection risk.
For developers building scalable scraping systems in 2026, the most effective strategy combines:
- Puppeteer Stealth for browser-level anti-detection
- Residential proxies for realistic network identity
- Human-like browsing simulation
- Distributed scraping infrastructure
By integrating high-quality residential proxy networks such as ColaProxy, developers can significantly improve scraping stability, reduce blocking rates, and build production-grade data extraction systems capable of operating in modern anti-bot environments.
Ultimately, the future of web scraping is no longer about bypassing websites with simple scripts.
It is about building infrastructure that behaves indistinguishably from real users.