Introduction
E-commerce data scraping has become an essential strategy for businesses, marketers, and developers looking to gain competitive insights in 2026. Among major retail platforms, Target remains a valuable source of product data, pricing intelligence, and consumer trends.
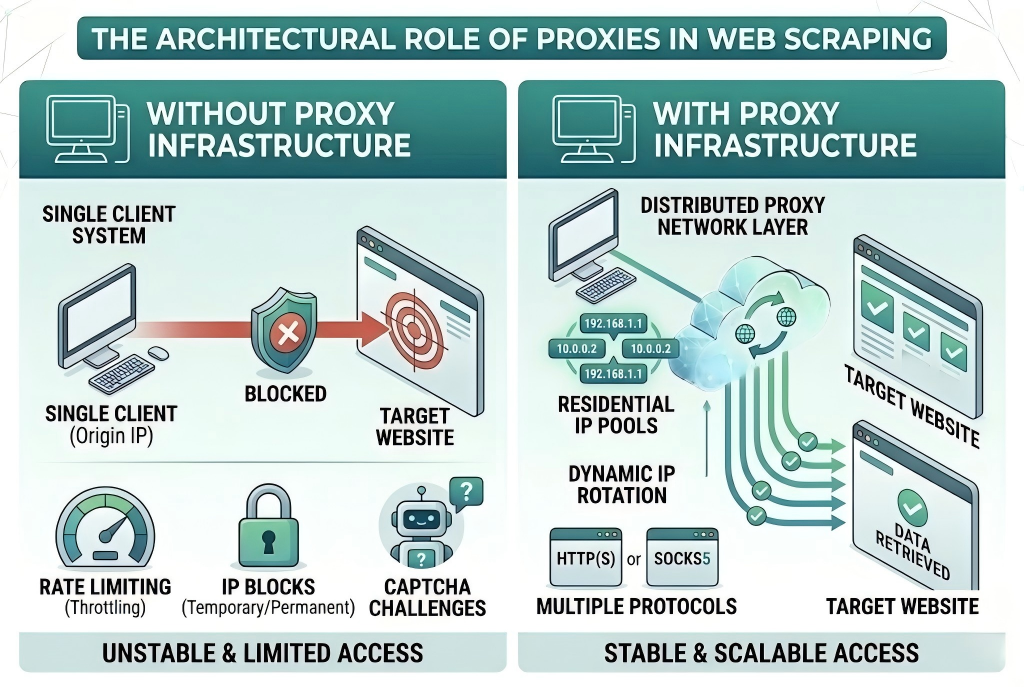
However, scraping Target product listings is no longer as simple as sending HTTP requests. Modern websites deploy advanced anti-bot systems, including IP blocking, behavioral analysis, and dynamic content loading.
To successfully scrape Target data at scale, you need a combination of:
- Reliable proxy infrastructure
- Advanced scraping tools
- Proper request handling strategies
In this guide, you’ll learn how to scrape Target product data step by step, including tools, challenges, and best practices using modern proxy solutions.

Why Scrape Target Product Data?
Before diving into the technical process, it’s important to understand the value of scraping Target data.
Key Use Cases
- Price Monitoring – Track competitor pricing in real time
- Product Research – Analyze trending items and categories
- Inventory Tracking – Monitor stock availability
- Market Analysis – Identify demand patterns
- Ad Optimization – Improve product positioning
These use cases are critical for e-commerce sellers, dropshippers, and data-driven businesses.
Why Target Is Difficult to Scrape in 2026
Target employs a multi-layer anti-bot defense system designed to detect non-human traffic patterns.
IP Reputation Filtering
Requests originating from repetitive or low-quality IP ranges are immediately flagged and throttled.
Behavioral Fingerprinting
Systems analyze:
- Mouse movement simulation
- Request timing consistency
- Header entropy
- Session repetition patterns
JavaScript-Rendered Data Layers
Critical product data is dynamically loaded via JavaScript, meaning static HTML scraping is insufficient.
Traffic Correlation Models
Modern systems correlate:
- Request frequency
- IP distribution patterns
- Session duration
to detect automation behavior.
👉 Conclusion: scraping failure is typically caused by predictable network behavior, not parsing logic.
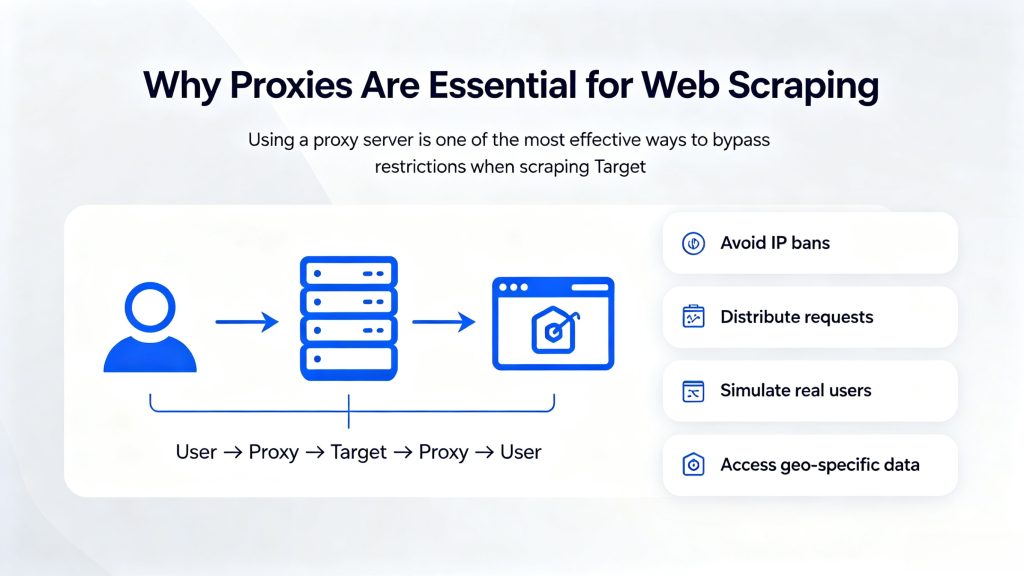
Why Proxies Are Essential for Web Scraping
Using a proxy server is one of the most effective ways to bypass restrictions when scraping Target.
What Proxies Do
A proxy routes your requests through different IP addresses:
User → Proxy → Target → Proxy → User
This helps:
- Avoid IP bans
- Distribute requests
- Simulate real users
- Access geo-specific data
Proxy Types and Their Impact on Success Rate
Residential Proxies
Use real ISP-assigned IPs, providing high trust and low detection probability.
Best suited for platforms with strict anti-bot systems.
Rotating Proxies
Automatically assign a new IP per request or session, enabling large-scale scraping without reuse patterns.
Datacenter Proxies
Offer high speed but lower trust levels, making them more prone to blocking.
| Proxy Type | Success Rate | Detection Risk | Best Use Case |
|---|---|---|---|
| Residential | High | Low | Target scraping |
| Datacenter | Medium | High | Low-risk tasks |
| Mobile | Very High | Very Low | Strict platforms |
Recommended Proxy Setup for Target Scraping
For best results, use:
- Residential rotating proxies
- Session control for stability
- Geo-targeting if needed
A provider like ColaProxy offers large-scale residential IP coverage and flexible rotation, which is suitable for high-volume scraping tasks.
Tools for Scraping Target Product Data
1. Python + Requests
Best for simple scraping tasks.
2. Selenium
Used for rendering JavaScript-heavy pages.
3. Playwright
Faster alternative to Selenium with better automation support.
4. Scraping APIs
Pre-built solutions that handle proxy rotation and CAPTCHA.
Step-by-Step Guide to Scrape Target Products
Step 1: Identify Target URLs
Find product listing or category pages, such as:
- Product pages
- Search result pages
- Category listings
Step 2: Inspect Page Structure
Use browser developer tools to locate:
- Product title
- Price
- Rating
- Availability
Step 3: Set Up Proxy Integration
Configure your scraper with a proxy:
Example (Python):
proxies = {
"http": "http://username:password@proxy:port",
"https": "http://username:password@proxy:port"
}Step 4: Send Requests
Use headers to mimic real users:
headers = {
"User-Agent": "Mozilla/5.0"
}Step 5: Parse Data
Use libraries like:
- BeautifulSoup
- lxml
Extract structured data from HTML.
Step 6: Handle Blocking
To avoid detection:
- Rotate IPs
- Randomize delays
- Use session control
Data Fields You Can Extract
| Field | Description |
|---|---|
| Product Name | Item title |
| Price | Current price |
| Rating | Customer reviews |
| Availability | In stock / out of stock |
| Category | Product classification |
Best Practices for Scraping Target Product Data
To achieve a stable and scalable scraping workflow, it is essential to implement a structured request strategy rather than relying on isolated optimizations. The following best practices are widely adopted in production-level scraping environments:
1. Use Rotating Residential Proxies
{kind=link}
Leverage high-quality residential proxy networks with automatic IP rotation to distribute requests across a large pool of real user IPs. This significantly reduces the risk of IP-based blocking and improves overall request success rates, especially when targeting platforms with strict anti-bot systems like Target.
2. Implement Intelligent Request Throttling
Avoid fixed or high-frequency request patterns. Instead, introduce dynamic delays between requests and apply rate-limiting logic to simulate natural user behavior. This helps prevent triggering automated defenses such as rate limiting and traffic anomaly detection.
3. Rotate Headers and User Agents
Ensure that each request includes varied and realistic HTTP headers, particularly User-Agent strings. By simulating different browsers, devices, and operating systems, you reduce the likelihood of being flagged as automated traffic.
4. Handle JavaScript-Rendered Content Properly
Since Target relies heavily on dynamic content loading, integrate browser automation frameworks such as Playwright or Selenium when necessary. This ensures accurate data extraction from JavaScript-rendered elements like pricing, inventory status, and product variations.
5. Monitor Success Rate and Implement Retry Logic
Continuously track request success rates, response status codes, and failure patterns. Implement retry mechanisms with exponential backoff to handle temporary blocks or network instability, ensuring data consistency and completeness.
6. Maintain Session Consistency When Required
For certain workflows (e.g., pagination or cart-based data), maintaining session persistence can improve stability. Use session-based proxy rotation strategies to balance between anonymity and continuity.
Common Mistakes to Avoid
- Using free proxies (unstable and unsafe)
- Sending high-frequency requests
- Ignoring headers and user agents
- Not handling dynamic content
Is Scraping Target Legal?
Web scraping legality depends on:
- Website terms of service
- Data usage
- Local regulations
Always ensure your scraping activities comply with applicable laws and ethical standards.
Future of Web Scraping in 2026
Web scraping is evolving with:
- AI-powered extraction tools
- Smarter anti-bot systems
- Increased need for high-quality proxies
Businesses that leverage scalable proxy infrastructure will have a significant advantage.
Conclusion
Scraping Target product data in 2026 requires a shift in thinking.
It is no longer about writing scripts—it is about designing resilient data acquisition systems.
A production-ready architecture must combine:
- Distributed residential proxy networks
- Adaptive request orchestration
- Browser-level rendering systems
Within this architecture, providers like ColaProxy serve as the underlying network layer, enabling large-scale, stable, and geographically distributed data extraction.
Ultimately, scraping success is determined not by code complexity, but by infrastructure design quality.