Web scraping has become a core infrastructure component for organizations that rely on large-scale public web data. It is widely used in scenarios such as pricing intelligence, market research, SEO analysis, and competitive monitoring.
However, modern websites increasingly deploy anti-bot systems, rate limiting mechanisms, and IP-based access controls. These constraints make direct access to target websites unstable in high-volume environments.
In this context, proxy infrastructure has become a standard component in web data collection systems.
Table of Contents
What Are Proxies in Web Scraping Systems?
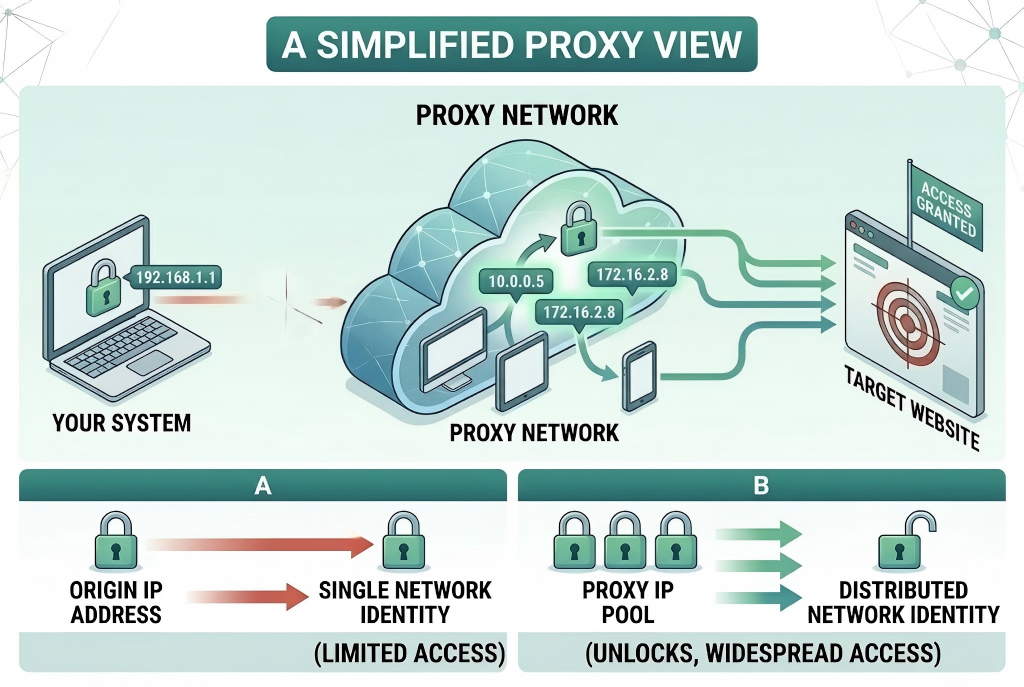
In web scraping architecture, proxies function as a network intermediary layer between the client system and target websites.
Instead of sending requests directly from a single origin IP address, traffic is routed through a distributed proxy network.
This abstraction layer allows request sources to be distributed across multiple IP addresses, reducing the dependency on a single network identity.
A typical proxy network used in web scraping environments includes:
- Residential proxy networks
- Datacenter proxy infrastructure
- Rotating proxy systems
- HTTP(S) and SOCKS5 proxy protocols
High-quality proxy providers (such as large-scale residential proxy networks) typically maintain continuously refreshed IP pools distributed across multiple geographic regions.
Why Web Scraping Relies on Proxy Infrastructure
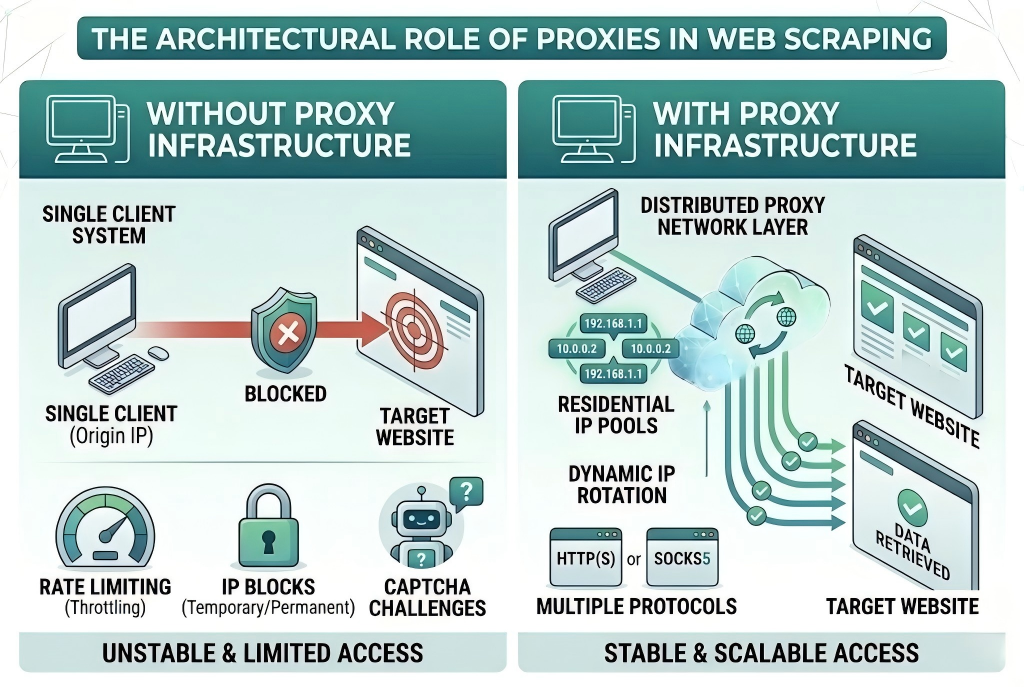
At scale, web scraping is not limited by request logic, but by access stability and network-level restrictions imposed by target systems.
Without proxy infrastructure, repeated requests from a single IP address can trigger:
- Rate limiting and throttling
- Temporary or permanent IP blocks
- CAPTCHA and verification challenges
- Restricted access to dynamic content layers
{kind=link}
Proxy networks solve these limitations by distributing outbound requests across multiple IP addresses, enabling more stable and scalable data acquisition workflows.
For this reason, proxy infrastructure is considered a foundational layer in modern scraping systems rather than an optional component.
Proxy Infrastructure in Production Environments
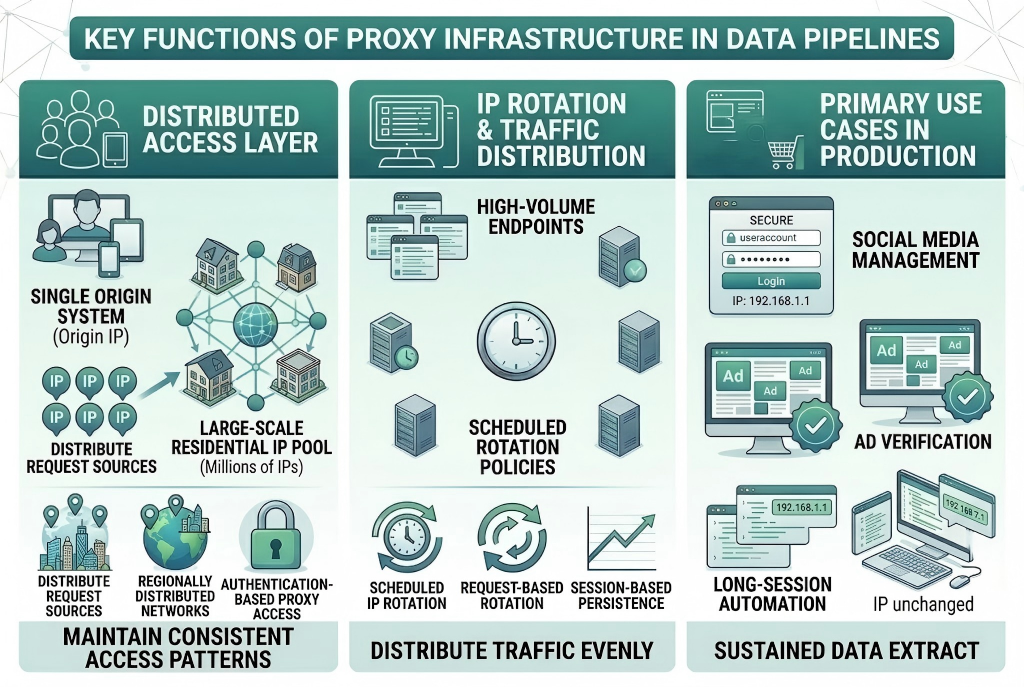
In production-grade scraping systems, proxies are typically integrated as part of a broader data pipeline architecture.
A proxy provider usually delivers access to:
- Large-scale residential IP pools
- Regionally distributed IP networks
- Rotating IP systems for traffic distribution
- Authentication-based proxy access (HTTP / SOCKS5)
These resources allow systems to maintain consistent access patterns while interacting with large volumes of web endpoints.
Types of Proxies Used in Web Scraping
Different proxy models are used depending on operational requirements and target system behavior.
Residential Proxies
Residential proxies are IP addresses assigned by Internet Service Providers (ISPs) to real devices. They are commonly used in environments where higher access authenticity and lower detection probability are required.
Datacenter Proxies
Datacenter proxies originate from cloud or hosting infrastructure. They are typically optimized for performance and throughput, making them suitable for high-speed request workloads.
Rotating Proxy Networks
Rotating proxy systems dynamically assign new IP addresses at the request or session level. This model is widely used in large-scale distributed scraping environments.
IP Rotation and Traffic Distribution Models
In modern proxy infrastructure, IP rotation is implemented at the system level rather than through manual randomization.
Common models include:
- Request-based rotation (new IP per request)
- Session-based persistence (stable IP per session)
- Scheduled rotation policies (time-based switching)
These mechanisms are designed to distribute traffic evenly across proxy pools and maintain consistent access behavior.
Residential vs Datacenter Proxies in Web Scraping
| Feature | Residential Proxies | Datacenter Proxies |
| Detection resistance | High | Medium |
| Speed | Medium | High |
| Cost structure | Higher | Lower |
| Use case | Anti-bot environments | High-volume requests |
| Access reliability | High | Varies by target system |
Residential proxy networks are generally preferred in environments with strict anti-bot protections, while datacenter proxies are often used for performance-driven workloads.
Common Use Cases of Proxy-Based Scraping Systems
Proxy infrastructure is widely applied in:
- E-commerce pricing intelligence and catalog monitoring
- Search engine result tracking (SERP data collection)
- Market research and competitive analysis
- Travel fare aggregation systems
- Advertising verification workflows
- Large-scale public data extraction pipelines
These use cases typically require sustained access to structured and unstructured web data across multiple regions and platforms.
Challenges Without Proxy Infrastructure
Without a proxy layer, web scraping systems are more likely to encounter structural limitations such as:
- Early-stage request blocking due to repeated IP usage
- Incomplete or inconsistent data retrieval
- Reduced scalability under distributed workloads
- Higher failure rates in long-running processes
These constraints are generally caused by network-level access policies rather than application-level logic.
Proxy Providers and Infrastructure Role
To support scalable web scraping operations, organizations typically rely on dedicated proxy providers that maintain large-scale IP infrastructure.
Such providers offer:
- Access to global residential IP networks
- High-availability proxy routing systems
- Rotating IP pools for traffic distribution
- Protocol-level support (HTTP(S), SOCKS5)
These capabilities enable consistent and scalable access to web data sources across different regions and platforms.
Conclusion
Proxies are a core infrastructure component in modern web scraping systems.
Rather than simply acting as an anonymity tool, proxy networks function as a distributed access layer that enables scalable, reliable, and regionally diversified data collection.
For organizations operating data-driven workflows such as price monitoring, SEO tracking, or market intelligence systems, proxy infrastructure is a fundamental requirement for maintaining stable access to web resources.