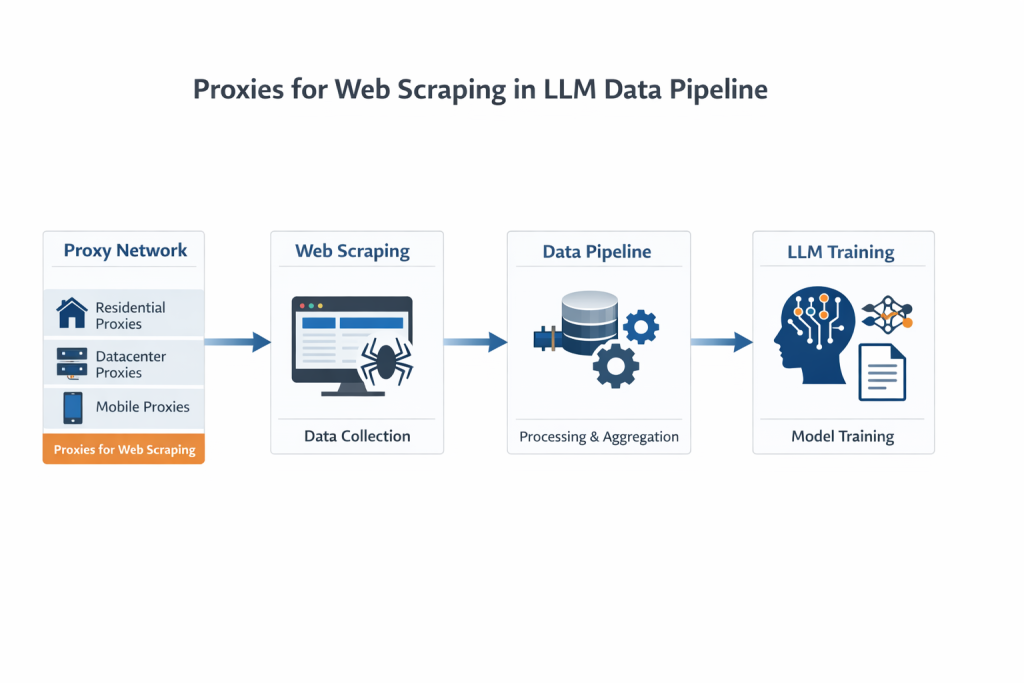
Proxies for Web Scraping are a critical foundation for modern LLM data pipelines. If you look at how large language models are built today, one thing becomes obvious pretty quickly:
It is not just about model architecture anymore.
It is about data — how much you can get, how diverse it is, and whether you can keep collecting it over time.
Most discussions focus on training techniques or model size. But in real-world systems, the harder problem is usually upstream:
how to reliably access web data at scale.
That is where web scraping and proxy infrastructure come in.
Table of Contents
Why LLMs Depend So Heavily on Data
LLMs are based on deep learning, typically Transformer architectures. Unlike traditional machine learning, they do not rely on manually defined features.
Instead, they learn patterns directly from raw text.
That sounds efficient, but it comes with a trade-off:
you need a lot more data.
Not just large volumes, but also at least 3 key dimensions:
- different writing styles
- different regions and languages
- different types of websites
And importantly, the data cannot be static. Models need updates, fine-tuning, and fresh input over time.
So in practice, LLM training is not a one-time dataset problem. It becomes a continuous data pipeline problem.
Why the Open Web Is Still the Primary Data Source
There are structured datasets, APIs, and licensed data sources. But none of them alone can match the scale and diversity of the open web.
So most teams eventually rely on web scraping.
At a small scale, scraping is straightforward. At a large scale, it becomes something else entirely.
The main challenge is no longer parsing HTML or extracting fields.
It is getting access consistently without being blocked.
Where Things Break Without Proxies
If you run a scraper from a single IP, it usually works for a while. In real-world systems, proxies for web scraping are essential to maintain stable and continuous access to web data. Then one of the following happens:
- requests start returning 429 errors
- CAPTCHA pages appear
- responses become incomplete
- eventually, the IP gets blocked
This is not unusual. It is how modern websites are designed to behave.
And the more aggressively you scale, the faster you hit those limits.
This is why, in production environments, proxies for web scraping are not optional. They are part of the system design from day one.
What Proxies Actually Do in LLM Pipelines
It is easy to think of proxies as a way to “hide your IP”. However, proxies for web scraping play a much broader role in large-scale data systems. That is technically correct, but not very useful.
In LLM data collection, proxies play a much broader role.
1. They Turn a Single Source Into a Distributed System
Instead of sending all requests from one machine, proxies let you spread traffic across many IPs.
That changes the behavior of your system completely:
- fewer blocks
- more stable request flow
- better scalability
This is essentially what people refer to when they talk about rotating proxies or proxy pools.
2. They Improve Data Reliability
Not all IPs are treated the same.
For example, residential proxies tend to behave more like real users, because they come from ISP-assigned devices.
In practice, this means:
- fewer detection triggers
- fewer CAPTCHA interruptions
- higher success rates
That is why residential proxies are commonly used in high-restriction scraping environments.
3. They Make Geo-Targeted Data Possible
A lot of web data is location-dependent.
Search results, prices, ads, even content structure can vary by region.
Without proxies, you are limited to the perspective of a single location.
With geo-targeted proxies, you can:
- request data from different countries
- compare regional variations
- build more representative datasets
For LLMs, this directly affects how well the model generalizes across regions.
4. They Support High-Concurrency Workloads
LLM data pipelines are rarely small.
They often involve:
- multiple concurrent jobs
- distributed workers
- long-running processes
To support that, you need:
- a large IP pool
- stable connections
- predictable performance
This is where proxy infrastructure starts to look less like a tool and more like a system dependency.
Choosing Between Proxy Types (Based on Real Needs)
There is no single “best” proxy type. It depends on what you are trying to do.
Datacenter Proxies
- fast and cost-efficient
- easier to detect
Good for:
- large-volume tasks
- low-restriction targets
Residential Proxies
- higher trust level
- better success rates
- slightly higher cost
Common choice for:
- large-scale web scraping
- anti-bot environments
ISP Proxies
- more stable than residential
- more trusted than datacenter
Used when both performance and reliability matter.
Mobile Proxies
- hardest to detect
- expensive
Usually reserved for very specific use cases.
Why Skipping Proxies Does Not Work
At some point, most teams consider reducing costs by avoiding proxies.
In theory, you could try to:
- slow down requests
- optimize scraping logic
- limit concurrency
In practice, this rarely holds up.
Different websites enforce different rules, and those rules change frequently.
What works today may fail tomorrow.
And once your IP is blocked, your data pipeline stops.
So the trade-off becomes clear:
You either invest in robust proxy infrastructure for web scraping, or accept unstable and unreliable data access.
The Real Relationship: LLMs, Scraping, and Proxies
It helps to think of the system as layers:
- LLMs consume data
- scraping systems collect data
- proxies enable access to data
Without proxies, the lower layer fails, and everything above it becomes unreliable.
So while proxies are not part of the model itself, they are part of what makes the model possible.
A Note on Compliance
Data collection is not just a technical problem.
You also need to consider:
- whether the data is public
- whether personal information is involved
- whether access requires authentication
In general:
- avoid scraping personal data
- avoid logged-in content
- follow applicable regulations
This is especially important for long-term projects.
What Good Proxy Usage Looks Like
In practice, stable systems usually include:
- some form of IP rotation (per request or per session)
- basic behavior simulation (delays, headers)
- monitoring (success rate, response time)
There is no perfect setup. Most teams iterate over time and adjust based on results.
Where Providers Like Cola Proxy Fit In
Building and maintaining proxy infrastructure internally is expensive.
That is why most teams rely on external providers.
Services like Cola Proxy typically offer:
- access to global residential IP pools
- rotating proxy systems
- support for HTTP(S) and SOCKS5
- flexible pricing models (GB-based or IP-based)
The goal is not just to provide IPs, but to make large-scale data access manageable.
If you’re building scalable data pipelines, choosing the right proxy solution matters. Check out our proxy services to get started with reliable data access.
Conclusion
At a high level, LLM development is about models.
At a practical level, it is about data.
And in real-world systems, it quickly becomes clear that access is the bottleneck.
Web scraping provides a way to collect data, while proxies for web scraping make it possible to do so consistently and at scale.
Without reliable proxy infrastructure, even the most advanced data pipelines become difficult to sustain.
Ultimately, proxies for web scraping are not just a supporting tool—they are a fundamental component of scalable LLM data pipelines.