Firecrawl alternatives are becoming increasingly important as web scraping evolves into a core part of modern data infrastructure.
As businesses scale their data collection efforts, challenges like IP bans, rate limiting, and anti-bot systems make it difficult to rely on a single tool. While Firecrawl simplifies scraping workflows, many teams are now actively looking for more scalable and reliable solutions.
In this guide, we explore the best Firecrawl alternatives in 2026, focusing on performance, flexibility, and the role of proxy infrastructure in building stable scraping systems.
Table of Contents
Why Businesses Are Moving Beyond Firecrawl
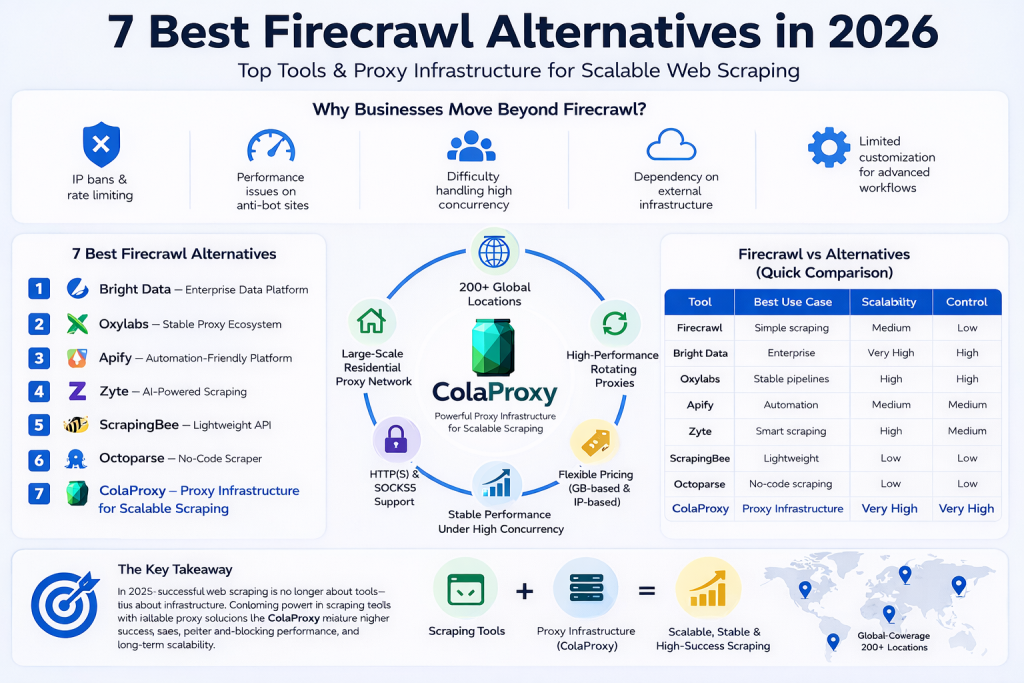
Firecrawl works well for simple scraping tasks. However, when scaling operations, many users begin searching for better Firecrawl alternatives due to several limitations:
- Limited control over proxy usage and IP rotation
- Performance issues on anti-bot protected websites
- Difficulty handling high concurrency
- Dependency on external infrastructure
- Limited customization for advanced workflows
These challenges highlight a key shift in the industry:
Modern web scraping is no longer just about tools—it is about infrastructure.
What Defines a Strong Firecrawl Alternative?
Beyond core features, the best Firecrawl alternatives also focus on stability under real-world conditions. This includes handling dynamic websites, JavaScript-heavy pages, and frequent anti-bot updates.
Another important factor is observability. Advanced platforms provide monitoring tools such as success rate tracking, request logs, and retry mechanisms, allowing developers to continuously optimize scraping performance.
In 2026, a strong Firecrawl alternative is not just defined by features, but by how well it performs under real-world pressure.
The best Firecrawl alternatives are no longer just scraping tools—they function as complete data acquisition systems designed for scalability and reliability.
Key features include:
- Integration with residential proxies
- Support for rotating proxy networks
- High success rate under anti-bot systems
- Distributed scraping capabilities
- Flexible API and automation support
- Scalability across regions and workloads
👉 For example, using residential proxies significantly improves success rates in web scraping.
7 Best Firecrawl Alternatives in 2026
1. Bright Data — Enterprise Data Platform
Best for: Large-scale enterprise scraping
Bright Data is one of the most established platforms in the web scraping industry, offering a full-stack solution that combines proxy networks with data collection tools. It is widely used by enterprises that require high success rates and global coverage.
Pros:
- Massive residential and mobile proxy network
- Advanced scraping APIs and data collection tools
- Strong anti-bot bypass capabilities
- Global targeting across multiple regions
Cons:
- Expensive compared to most alternatives
- Complex setup for beginners
2. Oxylabs — Stable Proxy Ecosystem
Best for: Long-term scraping pipelines
Oxylabs is known for its high-quality proxy infrastructure and consistent performance. It focuses on reliability and stability, making it a strong choice for businesses running continuous data extraction workflows.
Pros:
- High-quality residential and datacenter proxies
- Strong uptime and reliability
- Good support for large-scale operations
Cons:
- Premium pricing
- Limited flexibility for smaller teams
3. Apify — Automation-Friendly Platform
Best for: Workflow automation and custom scraping
Apify is designed for developers who want flexibility in building automated scraping workflows. It provides a cloud platform with pre-built actors and supports custom scripts.
Pros:
- Easy integration with APIs and workflows
- Large library of ready-to-use scraping tools
- Supports custom automation logic
Cons:
- Limited control over underlying proxy infrastructure
- Can become complex for large-scale systems
4. Zyte — AI-Powered Scraping
Best for: Intelligent and adaptive scraping
Zyte (formerly Scrapinghub) leverages AI to optimize scraping processes, including automatic proxy management and request handling. It is suitable for users who want a more automated approach.
Pros:
- AI-driven scraping optimization
- Built-in proxy rotation
- Handles complex anti-bot scenarios
Cons:
- Less transparency in how requests are handled
- Limited fine-grained control
5. ScrapingBee — Lightweight API
Best for: Simple and quick scraping tasks
ScrapingBee provides an easy-to-use API that handles headless browsers and proxy rotation internally. It is ideal for developers who want to avoid managing infrastructure.
Pros:
- Very easy to set up and use
- Built-in proxy and browser handling
- Good for small to medium projects
Cons:
- Limited scalability for large workloads
- Less suitable for complex scraping needs
6. Octoparse — No-Code Scraper
Best for: Beginners and non-technical users
Octoparse is a no-code scraping tool with a visual interface, allowing users to extract data without programming knowledge. It is often used for simple data collection tasks.
Pros:
- Visual, user-friendly interface
- Fast setup with templates
- No coding required
Cons:
- Limited scalability for enterprise use
- Less flexible for complex workflows
7. ColaProxy — Proxy Infrastructure for Scalable Scraping
Unlike traditional Firecrawl alternatives, ColaProxy focuses on the core layer that determines scraping success: proxy infrastructure.
In large-scale scraping, failures are usually caused by IP blocking—not by the scraper itself.
ColaProxy helps solve this by providing:
- Large-scale residential proxy network
- High-performance rotating proxies
- Global coverage across 200+ locations
- Support for HTTP(S) and SOCKS5
- Flexible pricing (GB-based and IP-based)
- Stable performance under high concurrency
👉 You can explore more about proxy pricing models here
Instead of replacing scraping tools, ColaProxy enhances them—making it one of the most practical Firecrawl alternatives for real-world use.
Why Proxy Infrastructure Matters More Than Scraping Tools
Many developers assume scraping issues come from tools—but in reality, most failures are caused by network restrictions.
Key factors include:
- IP quality (residential vs datacenter proxies)
- Rotation strategy
- Geographic targeting
- Detection resistance
Without a proper proxy for web scraping, even the best tools will fail at scale.
For more details, you can learn more about web scraping.
Firecrawl vs Alternatives (Quick Comparison)
| Tool | Best Use Case | Scalability | Control |
|---|---|---|---|
| Firecrawl | Simple scraping | Medium | Low |
| Bright Data | Enterprise | Very High | High |
| Oxylabs | Stable pipelines | High | High |
| Apify | Automation | Medium | Medium |
| Zyte | Smart scraping | High | Medium |
| ScrapingBee | Lightweight | Low | Low |
| ColaProxy | Proxy infrastructure | Very High | Very High |
Final Thoughts
Choosing the right Firecrawl alternatives is only part of the equation.
To build a scalable scraping system, you also need reliable proxy infrastructure.
By combining scraping tools with solutions like ColaProxy, businesses can achieve:
- Higher success rates
- Better anti-blocking performance
- Scalable data collection
- Long-term stability
In 2026, successful web scraping is no longer about tools—it is about infrastructure.