
概括
如果您发现网页抓取被阻止,您并非孤例。现代网站采用复杂的反机器人措施,例如TLS指纹识别和行为分析,来阻止自动数据收集。最快捷、最可靠的解决方法是将低端数据中心IP地址迁移到高质量的轮换住宅代理。通过将顶级代理基础设施与类人请求模式和正确的标头管理相结合,您可以绕过99%的抓取保护措施。
本指南提供了一个经过验证的框架,可帮助您恢复数据流并扩展提取项目,而无需担心永久IP封禁。
网络爬虫再次被屏蔽?数据提取过程中的无声挫败感
每个开发者都遇到过这种情况:脚本运行完美,数据源源不断地涌入,突然间——一片寂静。更糟糕的是,屏幕上出现一连串的403 Forbidden错误。当你发现网页抓取被阻止时,这表明目标网站的安全机制已将你的自动化操作标记为“非人为操作”。
在当今的网络环境下,网络抓取不再仅仅是发送一个GET请求那么简单。网站配备了由生成式引擎优化的防御机制,会寻找你数字指纹中最细微的异常。无论你是想从网站抓取数据进行市场调研还是获取竞争对手的价格信息,了解拦截背后的“原因”是找到解决方法的第一步。
为什么网站会阻止网络抓取?
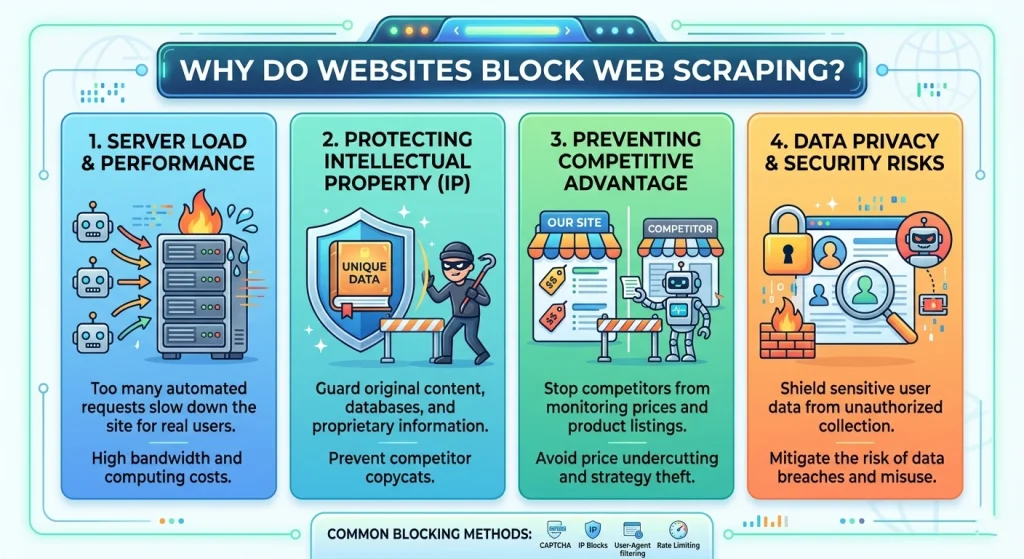
在深入探讨解决方案之前,我们必须了解原因。网站保护数据主要出于以下三个原因:
- 资源保护:机器人会消耗大量带宽和CPU资源,从而降低网站对真实用户的访问速度。
- 数据货币化:许多平台更倾向于通过官方API出售数据,而不是让数据通过爬虫网站“窃取”。
- 竞争优势:电子商务巨头经常屏蔽数据抓取工具,以防止竞争对手实时降低其价格。
如何找出网络爬虫被阻止的原因
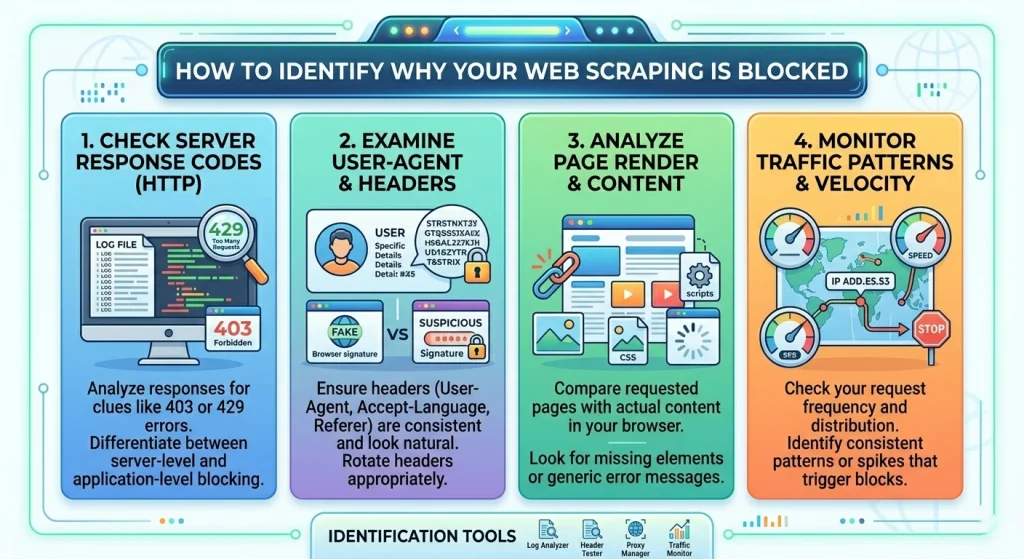
在实施修复之前,您需要诊断遇到的具体阻塞类型。并非所有的“阻塞”都相同。
常见错误信号
- HTTP 403禁止访问:服务器理解请求,但拒绝执行。这是典型的“你是机器人”信号。
- HTTP 429请求过多:您已达到速率限制。您的爬虫网站需要降低速度或轮换IP地址。
- 验证码墙:网站怀疑你是机器人,并要求你证明你是人类。
- TCP重置/超时:服务器在网络层面完全断开了您的连接。
5个快速解决网页抓取阻塞的有效策略
要想高效地抓取互联网数据,你需要多层防御。基于ColaProxy多年来协助企业级数据项目的经验,以下是最有效的几种方法。
1.实施高级IP轮换
网络爬虫被封禁的首要原因是使用同一个IP地址发出过多请求。
解决方法:使用大量的IP地址。但是,IP地址的类型比数量更重要。
- 数据中心代理:速度快,但很容易被识别为“服务器端”流量。
- 轮换住宅代理:这是黄金标准。它们使用真实家庭设备的IP地址,使你的机器人与普通用户无法区分。
2.掌握用户代理和标头轮换
你的HTTP请求头会透露很多信息。如果你的请求头显示你是“Python-requests/2.28”,那么你基本上就是在告诉别人“我是个机器人”。
解决方法:您必须模拟现代浏览器。
- 轮换用户代理:使用fake-useragent之类的库在Chrome、Firefox和Safari字符串之间切换。
- 匹配标头:确保您的Accept-Language、Referer和Connection标头与您声称的浏览器配置文件匹配。
3.绕过浏览器指纹识别
像Cloudflare和Akamai这样的现代反机器人程序不仅会查看你的IP地址,还会查看你的“指纹”——你的屏幕分辨率、字体,甚至你的浏览器渲染图形的方式(Canvas指纹识别)。
解决方法:使用“隐形”无头浏览器。
如果你要抓取任何具有严格保护措施的网站,请使用带有“隐形”插件的Playwright或Puppeteer。这样可以隐藏navigator.webdriver标志并模拟一致的硬件签名。
4.自动处理验证码
看到验证码并不意味着你的项目结束了,而是意味着你的“信任评分”下降了。
解决方法:预防:切换到ColaProxy的轮换移动代理通常可以完全阻止CAPTCHA,因为移动IP的信任评级最高。
- 解决方案:将CAPTCHA破解服务API(例如2Captcha)集成到您的工作流程中作为备用方案。
5.节流和类人行为
人不可能以每秒10次点击的速度,每次点击之间正好间隔100毫秒。
解决方法:引入random.uniform()延迟。
- 将URL请求顺序随机化。
- 偶尔“点击”一些非必要元素,以模拟真实的用户操作流程。
选择合适的代理:对比表
| 代理类型 | 检测风险 | 速度 | 最适合 |
| 动态住宅 | 极低 | 中等 | 高安全性网站(亚马逊、谷歌、社交媒体) |
| 动态数据中心 | 高 | 速度极快 | 具备基本防护的网站;高速任务 |
| 静态ISP代理 | 低 | 快速 | 账户管理;保持会话一致性 |
| 移动代理 | 最低 | 多变 | 绕过最难的403封锁和验证码 |
网络爬虫屏蔽困扰的用户,我们建议首先使用我们的轮换住宅代理。它们在隐蔽性和性价比之间实现了最佳平衡。
案例研究:零售商如何节省40多个小时的调试时间
我们的一位客户试图从一个大型全球市场网站抓取数据。他们使用了5000个数据中心代理服务器。运行开始不到10分钟,他们90%的请求就被阻止了。
他们改用ColaProxy,并实施了三项具体变更:
- 已移至轮换住宅代理。
- 使用Python实现网页爬虫,并利用cookie来维持会话持久性。
- 随机化他们的请求间隔。
结果:他们的成功率一夜之间从12%飙升至99.4%。他们不再需要手动“照看”脚本来轮换失效代理。
内部资源助力更高效的数据抓取
为了进一步优化您的设置,请浏览我们的深度技术博客:
- 如何在不触发“检测到机器人”屏幕的情况下抓取零售价格?
- 7个行之有效的步骤:如何轻松设置住宅代理
- 避免被封号:住宅IP轮换的科学原理
- 开发者指南:如何在Python爬虫中集成轮换代理
- 如何通过切换到高信任度住宅IP地址来解决验证码问题
常见问题解答(FAQ)
当我的网络爬虫被阻止时,我应该做的第一件事是什么?
检查状态码。如果是403,请更改用户代理并切换到高质量的住宅代理。如果是429,请增加请求之间的延迟。
我可以抓取任何网站的数据吗?
从技术上讲,大多数公共数据都可以被抓取,但您必须遵守网站的robots.txt文件和服务条款。请务必咨询法律专家,了解在您所在司法管辖区内网络抓取是否合法。
为什么谷歌会屏蔽网络爬虫?
谷歌利用先进的机器学习技术来检测非人类流量模式。他们会寻找来自云服务提供商IP地址段的高频请求。为了绕过这种检测,你需要轮换使用看起来像是合法智能手机用户的移动代理。
如何防止他人抓取我网站上的数据?
为了保护您自己的数据,请实施速率限制、使用Web应用防火墙(WAF)并监控已知的数据中心IP地址范围。但是,请注意,使用住宅IP地址的高端爬虫程序很难完全阻止。
什么是基于请求的爬虫?
这指的是不使用浏览器直接发出HTTP请求(例如使用axios或requests等工具)。这种方式速度更快、成本更低,但由于不执行JavaScript,因此更容易被网络爬虫拦截。
网络爬虫成功检查清单
在启动下一个大型项目之前,请使用此清单确保您的网络爬虫功能未被屏蔽:
- IP地址来源:您是否使用住宅IP地址或移动IP地址攻击高安全目标?
- 轮换:您的IP轮换逻辑是否由代理提供商自动处理?
- 标头:您是否已随机化User-Agent并添加了真实的Referer?
- 限流:请求之间是否存在随机延迟(例如,2-5秒)?
- 指纹识别:如果该网站使用大量JS代码进行保护,您是否使用了隐蔽配置的无头浏览器?
- 会话管理:您是否正确处理cookie以模拟连续的用户会话?
最终要点:不要让障碍阻碍你的进步
在数据科学和Web开发领域,网页抓取被屏蔽是一个常见的难题。但这并非放弃的信号,而是升级基础设施的契机。摒弃“廉价”方案,投资ColaProxy的专业代理服务,您将获得从网页资源抓取任何规模数据所需的工具。
准备好彻底解决您的网络屏蔽问题了吗?查看我们的轮换住宅代理定价,立即开始像专业人士一样进行网络爬虫工作。
参考文献及权威性:
- 有关机器人检测的行业标准,请参阅OWASPWeb应用程序自动化威胁。
- 有关403和429等状态代码的更深入了解,请参阅W3CHTTP/1.1标准。
- 电子前沿基金会(EFF)了解更多关于数据提取的法律先例。